来源:DeepTech深科技
要提高算力,我们通常首先想到提高单个芯片的处理速度,但实际上,芯片之间的通信速度同样关键。在计算机网络通信中,带宽和延迟是两个关键衡量指标,而对于 AI 网络来说,这一点同样适用。
对于训练上千亿甚至万亿参数的大规模模型来说,单个 GPU 的处理能力已经显得微不足道,计算任务往往需要由大型显卡集群协同完成。
然而,当前 GPU 内存容量和性能正在迅速增长,但输入/输出(I/O)性能的增长却相对滞后,这成了 AI 算力提升的重要瓶颈,导致了大量计算资源未被充分利用,造成了资源浪费。
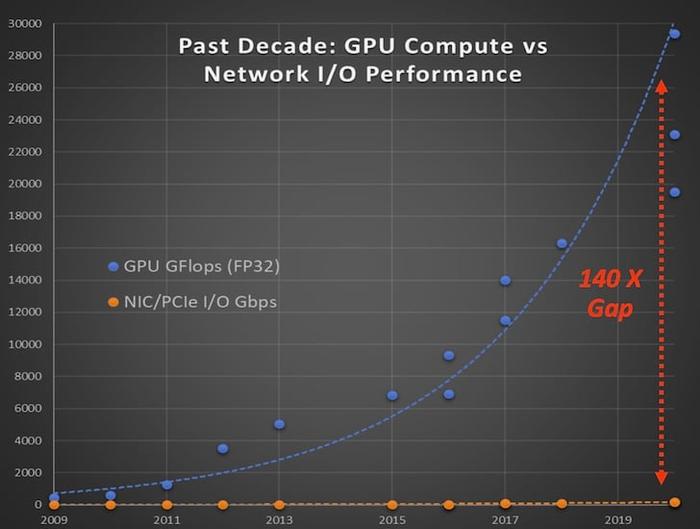
图丨网络 I/O 性能跟不上 GPU 计算性能(来源:Enfabrica)
由于传统 PCIe 协议的发展依然落后于时代需求,英伟达转而开发专有接口协议 NVLink 来应对这一问题,也借此掌控了行业内的话语权。
与之不同是,一家名为 Enfabrica 的初创公司则选择开发网络互联芯片,通过提供一种替代的扩展方式,融入现有 AI 算力体系中,以实现更高效的数据传输,从而减少算力闲置,整体上提高算力系统的利用率。
2024 年 11 月 19 日,在 2024 年超级计算大会 (SC24) 上,该公司宣布,继去年获得包括 NVIDIA 在内的 1.25 亿美元 B 轮融资后,已完成 1.15 亿美元的 C 轮融资。
这轮融资由 Spark Capital 领投,ARM、思科、三星等参投等,并得到了现有投资者的支持。
同时,Enfabrica 还宣布将于 2025 年第一季度推出其 3.2Tbps 加速计算结构 (Accelerated Compute Fabric,ACF) SuperNIC 芯片和试点系统。

图丨 SuperNIC 芯片(来源:Enfabrica)
据了解,ACF SuperNIC 芯片采用了一种融合纵向扩展(Scale-Up)和横向扩展(Scale-Out)的混合架构,形成了一个多维度的高带宽域。
传统网络架构通常依赖于标准以太网网络和 PCIe 交换机来实现扩展,但这种方式会遇到带宽瓶颈和延迟管理的问题。
而 ACF SuperNIC 通过结合高基数的 800、400 和 100 千兆以太网接口、32 个网络端口和 160 个 PCIe 通道,通过更高效的两层网络设计,能够支持超过 50 万 GPU 的 AI 集群,从而实现集群中所有 GPU 的最高横向扩展吞吐量和最低的端到端延迟。
ACF SuperNIC 的设计目标是用其加速计算结构替代传统的多层网络基础设施,实现计算、内存和网络资源的可组合 AI 结构。
据 Enfabrica 的联合创始人 Sankar 解释,该架构充当中心辐射模型,能够分解和扩展任意计算资源。
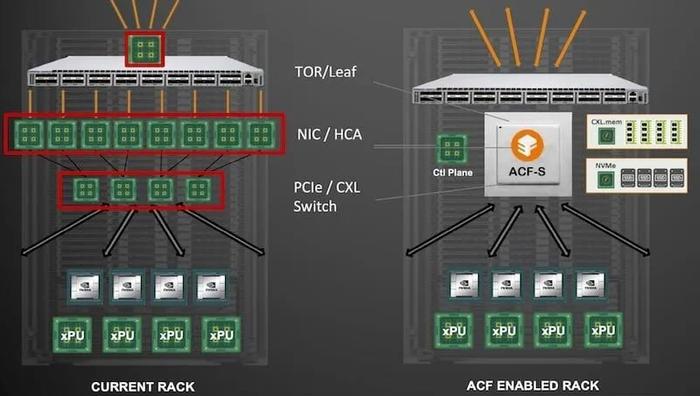
图丨 AFC 旨在取代多个网络层以提高性能(来源:Enfabrica)
无论是 CPU、GPU、加速器、内存还是闪存,它们都可以连接到这个中心,从而使 ACF-S 有效地充当这些计算资源的聚合 I/O 结构设备。
这种集线器式架构为计算、内存和网络资源的灵活组合提供了基础,实现了更高的可扩展性和计算效率。
该芯片基于台积电的 5 纳米 FinFET 工艺上制造,采用标准的硬件和软件接口,包括多端口 800 GbE 网络、高性能 PCIe Gen5,以及 CXL 2.0+ 接口。
在单个硅片中集成了多太比特交换和异构计算与内存资源之间的桥接,通过集体内存分区,在多个端点之间实现低延迟零拷贝数据传输,提供更高效的主机内存管理和突发带宽,从而共同提高 GPU 服务器群的整体效率和每秒浮点运算 (FLOP) 的利用率。
并且,ACF SuperNIC 所采用的标准接口,可以在不改变设备驱动程序和协议的情况下,在 CXL 3.0 到来之前实现内存扩展和共享,同时未来也兼容 CXL 3.0 标准。
这为数据中心运营商提供了巨大的运营效率优势,使他们可以在由来自多个供应商的 GPU 和加速器组成的 AI 计算队列中部署通用的高性能后端网络结构。
与此同时,该芯片所具有的“弹性消息多路径”(RMM)技术,可大规模提高 AI 集群的弹性、可维护性和正常运行时间,消除由于网络链路故障导致的 AI 作业停滞,从而提高有效训练时间和 GPU 计算效率,无需更改 AI 软件堆栈或网络拓扑。

图丨 Enfabrica 的 ACF SuperNIC 网络硬件的效果图(来源:Enfabrica)
Enfabrica 称,ACF SuperNIC 使客户能够在相同的性能点上将大型语言模型 (LLM) 推理的 GPU 计算成本降低约 50%,深度学习推荐模型 (DLRM) 推理的成本降低 75%。
该芯片将于 2025 年第一季度开始供货。该公司预计,到 2027 年,其 SFA 芯片的互连市场规模将达到 200 亿美元,主要目标客户包括公有云和私有云运营商、HPC 系统制造商和网络设备制造商。
未来,随着 AI 模型的规模不断扩大以及算力需求的提升,AI 芯片互联市场或将继续壮大。
根据 Dell'Oro Group 的数据,到 2027 年,人工智能基础设施投资将使数据中心资本支出增加到 5000 亿美元以上。
与此同时,根据 650 Group 的数据,到 2027 年,数据中心在计算、存储和网络芯片上的高性能 I/O 芯片支出预计将翻一番,达到 200 亿美元以上。
除了 Enfabrica 之外,思科也于去年推出了支持 AI 网络工作负载的 Silicon One G200 和 G202 硬件系列。
其他竞争对手如 Broadcom 和 Marvell 也在积极研发高性能交换机,博通的 Jericho3-AI 架构甚至可以连接多达 32,000 个 GPU。在中国,国数集联也于今年 4 月推出了业界首款 CXL 多级网络交换机参考设计。
背靠英伟达的 Enfabrica 能否实现其目标,还有待市场的检验。
参考资料:
1.https://www.businesswire.com/news/home/20241119607725/en/Enfabrica-Raises-115M-in-New-Funding-to-Advance-its-Leadership-in-AI-Networking-Solutions
2.https://www.allaboutcircuits.com/news/startup-enfabricas-accelerate-compute-fabric-addresses-ai-ml-in-the-cloud/
3.https://nowlab.cse.ohio-state.edu/static/media/workshops/presentations/exacomm24/ISC%202024-talk_final%20(1).pptx.pdf
4.https://blog.enfabrica.net/press-release-enfabrica-announces-availability-of-worlds-fastest-gpu-network-interface-controller-e7223fb98aa1
5.https://techcrunch.com/2023/09/12/enfabrica-which-builds-networking-hardware-to-drive-ai-workloads-raises-125m/
运营/排版:何晨龙